Семантическое ядро — как составить правильно? Составляем семантическое ядро своими руками: онлайн и программы Составление семантического ядра.
Всем-всем привет!
Что делать с семантическим ядром? Этим вопрос задаются, наверное, все новички в SEO-продвижении (сужу по себе) и не зря. Ведь реально на начальных порах человеку не понятно для чего он столько сидел и собирал ключевые слова для сайта, либо с использованием другим инструментов. Коль я тоже мучался с этим вопросом долго, то выпущу, пожалуй, урок на данную тему.
С какой целью собирается семантическое ядро?
Во-первых, давайте разберемся для чего вообще мы собирали семантическое ядро. Итак, все SEO-продвижение строится на использовании ключевых слов, которые вводят в поисковые строки пользователи. Благодаря им, создаются такие вещи, как структура сайта и его контент, что по сути является основными факторами во .
Также не стоит забывать и про внешнюю оптимизацию, в которой семантическое ядро играет немаловажную роль. Но об этом в следующих уроках.
Резюмирую: СЯ необходимо для:
- Создания структуры сайта, которая будет понятна как поисковым машинам, так и обычным пользователям;
- Создания контента. Контент в наше время является главным способом продвижения сайта в выдаче. Чем качественнее контент, тем сайт находится выше; чем больше качественного контента, тем сайт находится выше. Подробнее о создании качественного контента , еще ;
Что делать с семантическим ядром после составления?
Итак, после того, как Вы составили семантическое ядро, то есть: собрали ключевые слова, провели чистку и сгруппировали их, можно приступать к формированию структуры сайта. По сути, когда Вы сгруппировали запросы так, как мы делали это в уроке №145, Вы уже создали структуру своего веб-ресурса:
Вам нужно лишь реализовать ее на сайте и все. Таким образом, Вы сформируете структуру не на основе того, что у Вас есть в ассортименте, а на основе спроса у потребителей. Поступив так, Вы принесете пользу не только веб-ресурсу с точки зрения SEO, но и правильно поступите с точки зрения бизнеса в целом. Не зря ведь говорят: если есть спрос, значит должно быть предложение.
Со структурой вроде бы разобрались, теперь перейдем к контенту. Опять таки сгруппировав запросы в Key Collector, Вы нашли темы для своего будущего контента, которым будете наполнять страницы. Для примера, возьмем группу “Горные велосипеды” и разобьем ее на небольшие подгруппы:

Таким образом, мы создали две подгруппы с ключевыми запросами под отдельные страницы. Ваша задача на данном этапе: сформировать группы (кластеры) так, чтобы каждый кластер содержал в себе семантически одинаковые ключевики, то есть одинаковые по смыслу.
Запомните одно правило: каждому кластеру отдельная страница .
Так, конечно, не очень удобно для начинающих группировать, так как нужно иметь определенную сноровку, поэтому покажу и другой способ формирования тем для статей. На этот раз воспользуемся Excel:

Уже на основе получившихся данных Вы можете формировать отдельные страницы.
Так провожу кластеризацию (группировку) я и меня вполне все устраивает. Думаю, что теперь Вы поняли, что делать с семантическим ядром после составления.
Возможно пример, приведенный в данном уроке, слишком общий, так как не дает конкретной картины. Я просто хочу донести до Вас саму суть действия, а дальше Вы уже сами поработайте головой. Поэтому прошу прощения заранее.
Если данный урок стал для Вас полезным и помог в решении проблемы, то поделитесь, пожалуйста, ссылкой в социальных сетях. И, конечно же, подписывайтесь на обновления блога, если Вы этого еще не сделали.
Удачи Вам, друзья!
До скорых встреч!
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его вместе!
Небольшое предисловие
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
- мозговой штурм - анализ базовых фраз и подготовка парсинга
- парсинг - расширение базовой семантики на основе Вордстат и других источников
- отсев - отсев после парсинга
- анализ - анализ частотности, сезонности, конкуренции и других важных показателей
- доработка - групировка, разделение коммерческих и информационных фраз ядра
О наиболее важных этапах сбора и пойдет речь ниже!
ВИДЕО - составление семантического ядра по конкурентам
Мозговой штурм при создании семантического ядра — напрягаем мозги
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
- seo блог
- сео блог
- блог про сео
- блог про seo
- продвижение
- продвижение проекта
- раскрутка
- раскрутка
- продвижение блогов
- продвижение блога
- раскрутка блогов
- раскрутка блога
- продвижение статьями
- статейное продвижение
- miralinks
- работа в sape
- покупка ссылок
- закупка ссылок
- оптимизация
- оптимизация страницы
- внутренняя оптимизация
- самостоятельная раскрутка
- как раскрутить ресурс
- как раскрутить свой сайт
- как раскрутить сайт самому
- как раскрутить сайт самостоятельно
- самостоятельная раскрутка
- бесплатная раскрутка
- бесплатное продвижение
- поисковая оптимизация
- как продвинуть сайт в яндексе
- как раскрутить сайт в яндексе
- продвижение под яндекс
- продвижение под гугл
- раскрутка в гугл
- индексация
- ускорение индексации
- выбор донора сайту
- отсев доноров
- раскрутка постовыми
- использование постовых
- раскрутка блогами
- алгоритм яндекса
- апдейт тиц
- апдейт поисковой базы
- апдейт яндекса
- ссылки навсегда
- вечные ссылки
- аренда ссылок
- арендованные ссылке
- ссылки с помесячной оплатой
- составление семантического ядра
- секреты раскрутки
- секреты раскрутки
- тайны seo
- тайны оптимизации
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :

Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Чистка семантики
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:
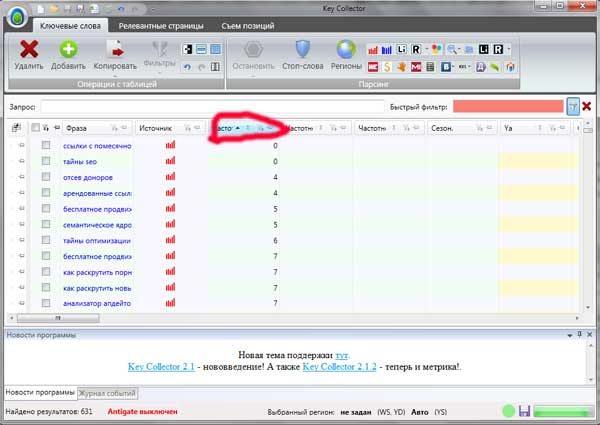
Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
курсы поисковой оптимизации продам раскрученный сайт
Анализ семантического ядра
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Экспорт и группировка семантического ядра
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:

Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
- такие частотные запросы, как должны иметь намного больший хвост из менее частотных фраз, чем мы видим
- сео новости
- всплыл новый ключ, который мы не учли ранее — статьи сео . Необходимо проанализировать этот ключ
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
- лучший seo блог
- seo новости
- статьи seo
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
Финальный отсев
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:
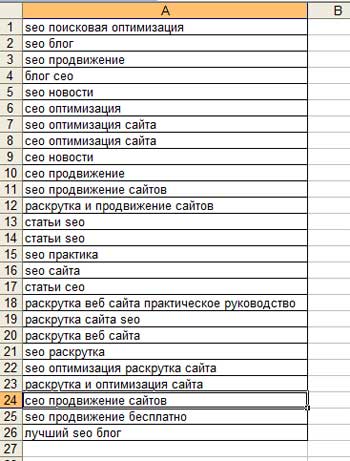

Затем проверяем стоимость получения одного перехода по нашим ключевым словам:
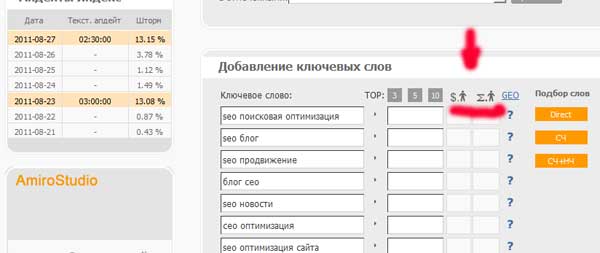
Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.

Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
Полезная информация!
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Кластеризация семантического ядра
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
- Подбор и анализ поисковых запросов
- Группировка запросов по страницам сайта (создание посадочных страниц)
- Подготовка seo текстов для посадочных страниц на основе группы запросов для этих страниц
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
- Один и тот же интент могут иметь несколько запросов не имеющих какой-либо семантической близости, например – “обслуживание автомобиля” и “записаться на ТО”
- Запросы, имеющие абсолютную семантическую близость могут содержать в себе кардинально разные интенты, например, хрестоматийная ситуация – “мобильник” и “мобильники”. В одном случае пользователь хочет купить телефон, а в другом посмотреть фильм
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
- Система поочередно вводит все поданные ей запросы в поисковую выдачу и запоминает результаты из ТОП
- После поочередного ввода запросов и сохранения результатов, система ищет пересечения в выдаче. Если один и тот же сайт одним и тем же документом (страница сайта) находится в ТОП сразу по нескольким запросам, то эти запросы теоретически можно объединить в одну группу
- Становится актуальным такой параметр, как сила группировки, который говорит системе, сколько именно должно быть пересечений, чтобы запросы можно было добавить в одну группу. К примеру, сила группировки 2 означает, что в выдаче по 2-м разным запросам должно присутствовать не менее двух пересечений. Говоря еще проще – минимум две страницы двух разных сайтов должны присутствовать одновременно в ТОП по одному и другому запросу. Пример ниже.
- При группировках больших семантики становится актуальна логика связей между запросами, на основе которой выделяют 3 базовых вида кластеризации: soft, middle и hard. О видах кластеризации мы еще поговорим в следующих записях этого дневника
Давайте напишем простое ядро, которое можно загрузить при помощи бутлоадера GRUB x86-системы. Это ядро будет отображать сообщение на экране и ждать.
Как загружается x86-система?
Прежде чем мы начнём писать ядро, давайте разберёмся, как система загружается и передаёт управление ядру.
В большей части регистров процессора при запуске уже находятся определённые значения. Регистр, указывающий на адрес инструкций (Instruction Pointer, EIP), хранит в себе адрес памяти, по которому лежит исполняемая процессором инструкция. EIP по умолчанию равен 0xFFFFFFF0 . Таким образом, x86-процессоры на аппаратном уровне начинают работу с адреса 0xFFFFFFF0. На самом деле это - последние 16 байт 32-битного адресного пространства. Этот адрес называется вектором перезагрузки (reset vector).
Теперь карта памяти чипсета гарантирует, что 0xFFFFFFF0 принадлежит определённой части BIOS, не RAM. В это время BIOS копирует себя в RAM для более быстрого доступа. Адрес 0xFFFFFFF0 будет содержать лишь инструкцию перехода на адрес в памяти, где хранится копия BIOS.
Так начинается исполнение кода BIOS. Сперва BIOS ищет устройство, с которого можно загрузиться, в предустановленном порядке. Ищется магическое число, определяющее, является ли устройство загрузочным (511-ый и 512-ый байты первого сектора должны равняться 0xAA55 ).
Когда BIOS находит загрузочное устройство, она копирует содержимое первого сектора устройства в RAM, начиная с физического адреса 0x7c00 ; затем переходит на адрес и исполняет загруженный код. Этот код называется бутлоадером .
Бутлоадер загружает ядро по физическому адресу 0x100000 . Этот адрес используется как стартовый во всех больших ядрах на x86-системах.
Все x86-процессоры начинают работу в простом 16-битном режиме, называющимся реальным режимом . Бутлоадер GRUB переключает режим в 32-битный защищённый режим , устанавливая нижний бит регистра CR0 в 1 . Таким образом, ядро загружается в 32-битном защищённом режиме.
Заметьте, что в случае с ядром Linux GRUB видит протоколы загрузки Linux и загружает ядро в реальном режиме. Ядро самостоятельно переключается в защищённый режим.
Что нам нужно?
- x86-компьютер;
- Linux;
- ld (GNU Linker);
Задаём точку входа на ассемблере
Как бы не хотелось ограничиться одним Си, что-то придётся писать на ассемблере. Мы напишем на нём небольшой файл, который будет служить исходной точкой для нашего ядра. Всё, что он будет делать - вызывать внешнюю функцию, написанную на Си, и останавливать поток программы.
Как же нам сделать так, чтобы этот код обязательно был именно исходной точкой?
Мы будем использовать скрипт-линковщик, который соединяет объектные файлы для создания конечного исполняемого файла. В этом скрипте мы явно укажем, что хотим загрузить данные по адресу 0x100000.
Вот код на ассемблере:
;;kernel.asm bits 32 ;nasm directive - 32 bit section .text global start extern kmain ;kmain is defined in the c file start: cli ;block interrupts mov esp, stack_space ;set stack pointer call kmain hlt ;halt the CPU section .bss resb 8192 ;8KB for stack stack_space:
Первая инструкция, bits 32 , не является x86-ассемблерной инструкцией. Это директива ассемблеру NASM, задающая генерацию кода для процессора, работающего в 32-битном режиме. В нашем случае это не обязательно, но вообще полезно.
Со второй строки начинается секция с кодом.
global - это ещё одна директива NASM, делающая символы исходного кода глобальными. Таким образом, линковщик знает, где находится символ start - наша точка входа.
kmain - это функция, которая будет определена в файле kernel.c . extern значит, что функция объявлена где-то в другом месте.
Затем идёт функция start , вызывающая функцию kmain и останавливающая процессор инструкцией hlt . Именно поэтому мы заранее отключаем прерывания инструкцией cli .
В идеале нам нужно выделить немного памяти и указать на неё указателем стека (esp). Однако, похоже, что GRUB уже сделал это за нас. Тем не менее, вы всё равно выделим немного места в секции BSS и переместим на её начало указатель стека. Мы используем инструкцию resb , которая резервирует указанное число байт. Сразу перед вызовом kmain указатель стека (esp) устанавливается на нужное место инструкцией mov .
Ядро на Си
В kernel.asm мы совершили вызов функции kmain() . Таким образом, наш “сишный” код должен начать исполнение с kmain() :
/* * kernel.c */ void kmain(void) { const char *str = "my first kernel"; char *vidptr = (char*)0xb8000; //video mem begins here. unsigned int i = 0; unsigned int j = 0; /* this loops clears the screen * there are 25 lines each of 80 columns; each element takes 2 bytes */ while(j < 80 * 25 * 2) { /* blank character */ vidptr[j] = " "; /* attribute-byte - light grey on black screen */ vidptr = 0x07; j = j + 2; } j = 0; /* this loop writes the string to video memory */ while(str[j] != "\0") { /* the character"s ascii */ vidptr[i] = str[j]; /* attribute-byte: give character black bg and light grey fg */ vidptr = 0x07; ++j; i = i + 2; } return; }
Всё, что сделает наше ядро - очистит экран и выведет строку “my first kernel”.
Сперва мы создаём указатель vidptr , который указывает на адрес 0xb8000 . С этого адреса в защищённом режиме начинается “видеопамять”. Для вывода текста на экран мы резервируем 25 строк по 80 ASCII-символов, начиная с 0xb8000.
Каждый символ отображается не привычными 8 битами, а 16. В первом байте хранится сам символ, а во втором - attribute-byte . Он описывает форматирование символа, например, его цвет.
Для вывода символа s зелёного цвета на чёрном фоне мы запишем этот символ в первый байт и значение 0x02 во второй. 0 означает чёрный фон, 2 - зелёный цвет текста.
Вот таблица цветов:
0 - Black, 1 - Blue, 2 - Green, 3 - Cyan, 4 - Red, 5 - Magenta, 6 - Brown, 7 - Light Grey, 8 - Dark Grey, 9 - Light Blue, 10/a - Light Green, 11/b - Light Cyan, 12/c - Light Red, 13/d - Light Magenta, 14/e - Light Brown, 15/f – White.
В нашем ядре мы будем использовать светло-серый текст на чёрном фоне, поэтому наш байт-атрибут будет иметь значение 0x07.
В первом цикле программа выводит пустой символ по всей зоне 80×25. Это очистит экран. В следующем цикле в “видеопамять” записываются символы из нуль-терминированной строки “my first kernel” с байтом-атрибутом, равным 0x07. Это выведет строку на экран.
Связующая часть
Мы должны собрать kernel.asm в объектный файл, используя NASM; затем при помощи GCC скомпилировать kernel.c в ещё один объектный файл. Затем их нужно присоединить к исполняемому загрузочному ядру.
Для этого мы будем использовать связывающий скрипт, который передаётся ld в качестве аргумента.
/* * link.ld */ OUTPUT_FORMAT(elf32-i386) ENTRY(start) SECTIONS { . = 0x100000; .text: { *(.text) } .data: { *(.data) } .bss: { *(.bss) } }
Сперва мы зададим формат вывода как 32-битный Executable and Linkable Format (ELF). ELF - это стандарный формат бинарных файлов Unix-систем архитектуры x86. ENTRY принимает один аргумент, определяющий имя символа, являющегося точкой входа. SECTIONS - это самая важная часть. В ней определяется разметка нашего исполняемого файла. Мы определяем, как должны соединяться разные секции и где их разместить.
В скобках после SECTIONS точка (.) отображает счётчик положения, по умолчанию равный 0x0. Его можно изменить, что мы и делаем.
Смотрим на следующую строку: .text: { *(.text) } . Звёздочка (*) - это специальный символ, совпадающий с любым именем файла. Выражение *(.text) означает все секции.text из всех входных файлов.
Таким образом, линковщик соединяет все секции кода объектных файлов в одну секцию исполняемого файла по адресу в счётчике положения (0x100000). После этого значение счётчика станет равным 0x100000 + размер полученной секции.
Аналогично всё происходит и с другим секциями.
Grub и Multiboot
Теперь все файлы готовы к созданию ядра. Но остался ещё один шаг.
Существует стандарт загрузки x86-ядер с использованием бутлоадера, называющийся Multiboot specification . GRUB загрузит наше ядро, только если оно удовлетворяет этим спецификациям .
Следуя им, ядро должно содержать заголовок в своих первых 8 килобайтах. Кроме того, этот заголовок должен содержать 3 поля, являющихся 4 байтами:
- магическое поле: содержит магическое число 0x1BADB002 для идентификации ядра.
- поле flags : нам оно не нужно, установим в ноль.
- поле checksum : если сложить его с предыдущими двумя, должен получиться ноль.
Наш kernel.asm станет таким:
;;kernel.asm ;nasm directive - 32 bit bits 32 section .text ;multiboot spec align 4 dd 0x1BADB002 ;magic dd 0x00 ;flags dd - (0x1BADB002 + 0x00) ;checksum. m+f+c should be zero global start extern kmain ;kmain is defined in the c file start: cli ;block interrupts mov esp, stack_space ;set stack pointer call kmain hlt ;halt the CPU section .bss resb 8192 ;8KB for stack stack_space:
Строим ядро
Теперь мы создадим объектные файлы из kernel.asm и kernel.c и свяжем их, используя наш скрипт.
Nasm -f elf32 kernel.asm -o kasm.o
Эта строка запустит ассемблер для создания объектного файла kasm.o в формате ELF-32.
Gcc -m32 -c kernel.c -o kc.o
Опция “-c” гарантирует, что после компиляции не произойдёт скрытого линкования.
Ld -m elf_i386 -T link.ld -o kernel kasm.o kc.o
Это запустит линковщик с нашим скриптом и создаст исполняемый файл, называющийся kernel .
Настраиваем grub и запускаем ядро
GRUB требует, чтобы имя ядра удовлетворяло шаблону kernel-
Теперь поместите его в директорию /boot . Для этого понадобятся права суперпользователя.
В конфигурационном файле GRUB grub.cfg добавьте следующее:
Title myKernel root (hd0,0) kernel /boot/kernel-701 ro
Не забудьте убрать директиву hiddenmenu , если она есть.
Перезагрузите компьютер, и вы увидите список ядер с вашим в том числе. Выберите его, и вы увидите:

Это ваше ядро! В добавим систему ввода / вывода.
P.S.
- Для любых фокусов с ядром лучше использовать виртуальную машину.
- Для запуска ядра в grub2 конфиг должен выглядеть так: menuentry "kernel 7001" { set root="hd0,msdos1" multiboot /boot/kernel-7001 ro }
- если вы хотите использовать эмулятор qemu , используйте: qemu-system-i386 -kernel kernel
Разработка ядра по праву считается задачей не из легких, но написать простейшее ядро может каждый. Чтобы прикоснуться к магии кернел-хакинга, нужно лишь соблюсти некоторые условности и совладать с ассемблером. В этой статье мы на пальцах разберем, как это сделать.
Привет, мир!
Давай напишем ядро, которое будет загружаться через GRUB на системах, совместимых с x86. Наше первое ядро будет показывать сообщение на экране и на этом останавливаться.
Как загружаются x86-машины
Прежде чем думать о том, как писать ядро, давай посмотрим, как компьютер загружается и передает управление ядру. Большинство регистров процессора x86 имеют определенные значения после загрузки. Регистр - указатель на инструкцию (EIP) содержит адрес инструкции, которая будет исполнена процессором. Его захардкоженное значение - это 0xFFFFFFF0. То есть x86-й процессор всегда будет начинать исполнение с физического адреса 0xFFFFFFF0. Это последние 16 байт 32-разрядного адресного пространства. Этот адрес называется «вектор сброса» (reset vector).
В карте памяти, которая содержится в чипсете, прописано, что адрес 0xFFFFFFF0 ссылается на определенную часть BIOS, а не на оперативную память. Однако BIOS копирует себя в оперативку для более быстрого доступа - этот процесс называется «шедоуинг» (shadowing), создание теневой копии. Так что адрес 0xFFFFFFF0 будет содержать только инструкцию перехода к тому месту в памяти, куда BIOS скопировала себя.
Итак, BIOS начинает исполняться. Сначала она ищет устройства, с которых можно загружаться в том порядке, который задан в настройках. Она проверяет носители на наличие «волшебного числа», которое отличает загрузочные диски от обычных: если байты 511 и 512 в первом секторе равны 0xAA55, значит, диск загрузочный.
Как только BIOS найдет загрузочное устройство, она скопирует содержимое первого сектора в оперативную память, начиная с адреса 0x7C00, а затем переведет исполнение на этот адрес и начнет исполнение того кода, который только что загрузила. Вот этот код и называется загрузчиком (bootloader).
Загрузчик загружает ядро по физическому адресу 0x100000. Именно он и используется большинством популярных ядер для x86.
Все процессоры, совместимые с x86, начинают свою работу в примитивном 16-разрядном режиме, которые называют «реальным режимом» (real mode). Загрузчик GRUB переключает процессор в 32-разрядный защищенный режим (protected mode), переводя нижний бит регистра CR0 в единицу. Поэтому ядро начинает загружаться уже в 32-битном защищенном режиме.
Заметь, что GRUB в случае с ядрами Linux выбирает соответствующий протокол загрузки и загружает ядро в реальном режиме. Ядра Linux сами переключаются в защищенный режим.
Что нам понадобится
- Компьютер, совместимый с x86 (очевидно),
- Linux,
- ассемблер NASM,
- ld (GNU Linker),
- GRUB.
Входная точка на ассемблере
Нам бы, конечно, хотелось написать все на C, но совсем избежать использования ассемблера не получится. Мы напишем на ассемблере x86 небольшой файл, который станет стартовой точкой для нашего ядра. Все, что будет делать ассемблерный код, - это вызывать внешнюю функцию, которую мы напишем на C, а потом останавливать выполнение программы.
Как сделать так, чтобы ассемблерный код стал стартовой точкой для нашего ядра? Мы используем скрипт для компоновщика (linker), который линкует объектные файлы и создает финальный исполняемый файл ядра (подробнее объясню чуть ниже). В этом скрипте мы напрямую укажем, что хотим, чтобы наш бинарный файл загружался по адресу 0x100000. Это адрес, как я уже писал, по которому загрузчик ожидает увидеть входную точку в ядро.
Вот код на ассемблере.
kernel.asm
bits 32 section .text global start extern kmain start: cli mov esp, stack_space call kmain hlt section .bss resb 8192 stack_space:Первая инструкция bits 32 - это не ассемблер x86, а директива NASM, сообщающая, что нужно генерировать код для процессора, который будет работать в 32-разрядном режиме. Для нашего примера это не обязательно, но указывать это явно - хорошая практика.
Вторая строка начинает текстовую секцию, также известную как секция кода. Сюда пойдет весь наш код.
global - это еще одна директива NASM, она объявляет символы из нашего кода глобальными. Это позволит компоновщику найти символ start , который и служит нашей точкой входа.
kmain - это функция, которая будет определена в нашем файле kernel.c . extern объявляет, что функция декларирована где-то еще.
Далее идет функция start , которая вызывает kmain и останавливает процессор инструкцией hlt . Прерывания могут будить процессор после hlt , так что сначала мы отключаем прерывания инструкцией cli (clear interrupts).
В идеале мы должны выделить какое-то количество памяти под стек и направить на нее указатель стека (esp). GRUB, кажется, это и так делает за нас, и на этот момент указатель стека уже задан. Однако на всякий случай выделим немного памяти в секции BSS и направим указатель стека на ее начало. Мы используем инструкцию resb - она резервирует память, заданную в байтах. Затем оставляется метка, указывающая на край зарезервированного куска памяти. Прямо перед вызовом kmain указатель стека (esp) направляется на эту область инструкцией mov .
Ядро на C
В файле kernel.asm мы вызвали функцию kmain() . Так что в коде на C исполнение начнется с нее.
kernel.c
void kmain(void) { const char *str = "my first kernel"; char *vidptr = (char*)0xb8000; unsigned int i = 0; unsigned int j = 0; while(j < 80 * 25 * 2) { vidptr[j] = " "; vidptr = 0x07; j = j + 2; } j = 0; while(str[j] != "\0") { vidptr[i] = str[j]; vidptr = 0x07; ++j; i = i + 2; } return; }Все, что будет делать наше ядро, - очищать экран и выводить строку my first kernel.
Первым делом мы создаем указатель vidptr, который указывает на адрес 0xb8000. В защищенном режиме это начало видеопамяти. Текстовая экранная память - это просто часть адресного пространства. Под экранный ввод-вывод выделен участок памяти, который начинается с адреса 0xb8000, - в него помещается 25 строк по 80 символов ASCII.
Каждый символ в текстовой памяти представлен 16 битами (2 байта), а не 8 битами (1 байтом), к которым мы привыкли. Первый байт - это код символа в ASCII, а второй байт - это attribute-byte . Это определение формата символа, в том числе - его цвет.
Чтобы вывести символ s зеленым по черному, нам нужно поместить s в первый байт видеопамяти, а значение 0x02 - во второй байт. 0 здесь означает черный фон, а 2 - зеленый цвет. Мы будем использовать светло-серый цвет, его код - 0x07.
В первом цикле while программа заполняет пустыми символами с атрибутом 0x07 все 25 строк по 80 символов. Это очистит экран.
Во втором цикле while символы строки my first kernel, оканчивающейся нулевым символом, записываются в видеопамять и каждый символ получает attribute-byte, равный 0x07. Это должно привести к выводу строки.
Компоновка
Теперь мы должны собрать kernel.asm в объектный файл с помощью NASM, а затем при помощи GCC скомпилировать kernel.c в другой объектный файл. Наша задача - слинковать эти объекты в исполняемое ядро, пригодное к загрузке. Для этого потребуется написать для компоновщика (ld) скрипт, который мы будем передавать в качестве аргумента.
link.ld
OUTPUT_FORMAT(elf32-i386) ENTRY(start) SECTIONS { . = 0x100000; .text: { *(.text) } .data: { *(.data) } .bss: { *(.bss) } }Здесь мы сначала задаем формат (OUTPUT_FORMAT) нашего исполняемого файла как 32-битный ELF (Executable and Linkable Format), стандартный бинарный формат для Unix-образных систем для архитектуры x86.
ENTRY принимает один аргумент. Он задает название символа, который будет служить входной точкой исполняемого файла.
SECTIONS - это самая важная для нас часть. Здесь мы определяем раскладку нашего исполняемого файла. Мы можем определить, как разные секции будут объединены и куда каждая из них будет помещена.
В фигурных скобках, которые идут за выражением SECTIONS , точка означает счетчик позиции (location counter). Он автоматически инициализируется значением 0x0 в начале блока SECTIONS , но его можно менять, назначая новое значение.
Ранее я уже писал, что код ядра должен начинаться по адресу 0x100000. Именно поэтому мы и присваиваем счетчику позиции значение 0x100000.
Взгляни на строку.text: { *(.text) } . Звездочкой здесь задается маска, под которую подходит любое название файла. Соответственно, выражение *(.text) означает все входные секции.text во всех входных файлах.
В результате компоновщик сольет все текстовые секции всех объектных файлов в текстовую секцию исполняемого файла и разместит по адресу, указанному в счетчике позиции. Секция кода нашего исполняемого файла будет начинаться по адресу 0x100000.
После того как компоновщик выдаст текстовую секцию, значение счетчика позиции будет 0x100000 плюс размер текстовой секции. Точно так же секции data и bss будут слиты и помещены по адресу, который задан счетчиком позиции.
GRUB и мультизагрузка
Теперь все наши файлы готовы к сборке ядра. Но поскольку мы будем загружать ядро при помощи GRUB , остается еще один шаг.
Существует стандарт для загрузки разных ядер x86 с помощью бутлоадера. Это называется «спецификация мультибута ». GRUB будет загружать только те ядра, которые ей соответствуют.
В соответствии с этой спецификацией ядро может содержать заголовок (Multiboot header) в первых 8 килобайтах. В этом заголовке должно быть прописано три поля:
- magic - содержит «волшебное» число 0x1BADB002, по которому идентифицируется заголовок;
- flags - это поле для нас не важно, можно оставить ноль;
- checksum - контрольная сумма, должна дать ноль, если прибавить ее к полям magic и flags .
Наш файл kernel.asm теперь будет выглядеть следующим образом.
kernel.asm
bits 32 section .text ;multiboot spec align 4 dd 0x1BADB002 ;magic dd 0x00 ;flags dd - (0x1BADB002 + 0x00) ;checksum global start extern kmain start: cli mov esp, stack_space call kmain hlt section .bss resb 8192 stack_space:Инструкция dd задает двойное слово размером 4 байта.
Собираем ядро
Итак, все готово для того, чтобы создать объектный файл из kernel.asm и kernel.c и слинковать их с применением нашего скрипта. Пишем в консоли:
$ nasm -f elf32 kernel.asm -o kasm.o
По этой команде ассемблер создаст файл kasm.o в формате ELF-32 bit. Теперь настал черед GCC:
$ gcc -m32 -c kernel.c -o kc.o
Параметр -c указывает на то, что файл после компиляции не нужно линковать. Мы это сделаем сами:
$ ld -m elf_i386 -T link.ld -o kernel kasm.o kc.o
Эта команда запустит компоновщик с нашим скриптом и сгенерирует исполняемый файл под названием kernel .
WARNING
Хакингом ядра лучше всего заниматься в виртуалке. Чтобы запустить ядро в QEMU вместо GRUB, используй команду qemu-system-i386 -kernel kernel .
Настраиваем GRUB и запускаем ядро
GRUB требует, чтобы название файла с ядром следовало конвенции kernel-<версия> . Так что переименовываем файл - я назову свой kernel-701 .
Теперь кладем ядро в каталог /boot . На это понадобятся привилегии суперпользователя.
В конфигурационный файл GRUB grub.cfg нужно будет добавить что-то в таком роде:
Title myKernel root (hd0,0) kernel /boot/kernel-701 ro
Не забудь убрать директиву hiddenmenu, если она прописана.
GRUB 2
Чтобы запустить созданное нами ядро в GRUB 2, который по умолчанию поставляется в новых дистрибутивах, твой конфиг должен выглядеть следующим образом:
Menuentry "kernel 701" { set root="hd0,msdos1" multiboot /boot/kernel-701 ro }
Благодарю Рубена Лагуану за это дополнение.
Перезагружай компьютер, и ты должен будешь увидеть свое ядро в списке! А выбрав его, ты увидишь ту самую строку.

Это и есть твое ядро!
Пишем ядро с поддержкой клавиатуры и экрана
Мы закончили работу над минимальным ядром, которое загружается через GRUB, работает в защищенном режиме и выводит на экран одну строку. Настала пора расширить его и добавить драйвер клавиатуры, который будет читать символы с клавиатуры и выводить их на экран.
Мы будем общаться с устройствами ввода-вывода через порты ввода-вывода. По сути, они просто адреса на шине ввода-вывода. Для операций чтения и записи в них существуют специальные процессорные инструкции.
Работа с портами: чтение и вывод
read_port: mov edx, in al, dx ret write_port: mov edx, mov al, out dx, al retДоступ к портам ввода-вывода осуществляется при помощи инструкций in и out , входящих в набор x86.
В read_port номер порта передается в качестве аргумента. Когда компилятор вызывает функцию, он кладет все аргументы в стек. Аргумент копируется в регистр edx при помощи указателя на стек. Регистр dx - это нижние 16 бит регистра edx . Инструкция in здесь читает порт, номер которого задан в dx , и кладет результат в al . Регистр al - это нижние 8 бит регистра eax . Возможно, ты помнишь из институтского курса, что значения, возвращаемые функциями, передаются через регистр eax . Таким образом, read_port позволяет нам читать из портов ввода-вывода.
Функция write_port работает схожим образом. Мы принимаем два аргумента: номер порта и данные, которые будут записаны. Инструкция out пишет данные в порт.
Прерывания
Теперь, прежде чем мы вернемся к написанию драйвера, нам нужно понять, как процессор узнает, что какое-то из устройств выполнило операцию.
Самое простое решение - это опрашивать устройства - непрерывно по кругу проверять их статус. Это по очевидным причинам неэффективно и непрактично. Поэтому здесь в игру вступают прерывания. Прерывание - это сигнал, посылаемый процессору устройством или программой, который означает, что произошло событие. Используя прерывания, мы можем избежать необходимости опрашивать устройства и будем реагировать только на интересующие нас события.
За прерывания в архитектуре x86 отвечает чип под названием Programmable Interrupt Controller (PIC). Он обрабатывает хардверные прерывания и направляет и превращает их в соответствующие системные прерывания.
Когда пользователь что-то делает с устройством, чипу PIC отправляется импульс, называемый запросом на прерывание (Interrupt Request, IRQ). PIC переводит полученное прерывание в системное прерывание и отправляет процессору сообщение о том, что пора остановить то, что он делает. Дальнейшая обработка прерываний - это задача ядра.
Без PIC нам бы пришлось опрашивать все устройства, присутствующие в системе, чтобы посмотреть, не произошло ли событие с участием какого-то из них.
Давай разберем, как это работает в случае с клавиатурой. Клавиатура висит на портах 0x60 и 0x64. Порт 0x60 отдает данные (когда нажата какая-то кнопка), а порт 0x64 передает статус. Однако нам нужно знать, когда конкретно читать эти порты.
Прерывания здесь приходятся как нельзя более кстати. Когда кнопка нажата, клавиатура отправляет PIC сигнал по линии прерываний IRQ1. PIС хранит значение offset , сохраненное во время его инициализации. Он добавляет номер входной линии к этому отступу, чтобы сформировать вектор прерывания. Затем процессор ищет структуру данных, называемую «таблица векторов прерываний» (Interrupt Descriptor Table, IDT), чтобы дать функции - обработчику прерывания адрес, соответствующий его номеру.
Затем код по этому адресу исполняется и обрабатывает прерывание.
Задаем IDT
struct IDT_entry{ unsigned short int offset_lowerbits; unsigned short int selector; unsigned char zero; unsigned char type_attr; unsigned short int offset_higherbits; }; struct IDT_entry IDT; void idt_init(void) { unsigned long keyboard_address; unsigned long idt_address; unsigned long idt_ptr; keyboard_address = (unsigned long)keyboard_handler; IDT.offset_lowerbits = keyboard_address & 0xffff; IDT.selector = 0x08; /* KERNEL_CODE_SEGMENT_OFFSET */ IDT.zero = 0; IDT.type_attr = 0x8e; /* INTERRUPT_GATE */ IDT.offset_higherbits = (keyboard_address & 0xffff0000) >> 16; write_port(0x20 , 0x11); write_port(0xA0 , 0x11); write_port(0x21 , 0x20); write_port(0xA1 , 0x28); write_port(0x21 , 0x00); write_port(0xA1 , 0x00); write_port(0x21 , 0x01); write_port(0xA1 , 0x01); write_port(0x21 , 0xff); write_port(0xA1 , 0xff); idt_address = (unsigned long)IDT ; idt_ptr = (sizeof (struct IDT_entry) * IDT_SIZE) + ((idt_address & 0xffff) << 16); idt_ptr = idt_address >> 16 ; load_idt(idt_ptr); }IDT - это массив, объединяющий структуры IDT_entry. Мы еще обсудим привязку клавиатурного прерывания к обработчику, а сейчас посмотрим, как работает PIC.
Современные системы x86 имеют два чипа PIC, у каждого восемь входных линий. Будем называть их PIC1 и PIC2. PIC1 получает от IRQ0 до IRQ7, а PIC2 - от IRQ8 до IRQ15. PIC1 использует порт 0x20 для команд и 0x21 для данных, а PIC2 - порт 0xA0 для команд и 0xA1 для данных.
Оба PIC инициализируются восьмибитными словами, которые называются «командные слова инициализации» (Initialization command words, ICW).
В защищенном режиме обоим PIC первым делом нужно отдать команду инициализации ICW1 (0x11). Она сообщает PIC, что нужно ждать еще трех инициализационных слов, которые придут на порт данных.
Эти команды передадут PIC:
- вектор отступа (ICW2),
- какие между PIC отношения master/slave (ICW3),
- дополнительную информацию об окружении (ICW4).
Вторая команда инициализации (ICW2) тоже шлется на вход каждого PIC. Она назначает offset , то есть значение, к которому мы добавляем номер линии, чтобы получить номер прерывания.
PIC разрешают каскадное перенаправление их выводов на вводы друг друга. Это делается при помощи ICW3, и каждый бит представляет каскадный статус для соответствующего IRQ. Сейчас мы не будем использовать каскадное перенаправление и выставим нули.
ICW4 задает дополнительные параметры окружения. Нам нужно определить только нижний бит, чтобы PIC знали, что мы работаем в режиме 80x86.
Та-дам! Теперь PIC проинициализированы.
У каждого PIC есть внутренний восьмибитный регистр, который называется «регистр масок прерываний» (Interrupt Mask Register, IMR). В нем хранится битовая карта линий IRQ, которые идут в PIC. Если бит задан, PIC игнорирует запрос. Это значит, что мы можем включить или выключить определенную линию IRQ, выставив соответствующее значение в 0 или 1.
Чтение из порта данных возвращает значение в регистре IMR, а запись - меняет регистр. В нашем коде после инициализации PIC мы выставляем все биты в единицу, чем деактивируем все линии IRQ. Позднее мы активируем линии, которые соответствуют клавиатурным прерываниям. Но для начала все же выключим!
Если линии IRQ работают, наши PIC могут получать сигналы по IRQ и преобразовывать их в номер прерывания, добавляя офсет. Нам же нужно заполнить IDT таким образом, чтобы номер прерывания, пришедшего с клавиатуры, соответствовал адресу функции-обработчика, которую мы напишем.
На какой номер прерывания нам нужно завязать в IDT обработчик клавиатуры?
Клавиатура использует IRQ1. Это входная линия 1, ее обрабатывает PIC1. Мы проинициализировали PIC1 с офсетом 0x20 (см. ICW2). Чтобы получить номер прерывания, нужно сложить 1 и 0x20, получится 0x21. Значит, адрес обработчика клавиатуры будет завязан в IDT на прерывание 0x21.
Задача сводится к тому, чтобы заполнить IDT для прерывания 0x21. Мы замапим это прерывание на функцию keyboard_handler , которую напишем в ассемблерном файле.
Каждая запись в IDT состоит из 64 бит. В записи, соответствующей прерыванию, мы не сохраняем адрес функции-обработчика целиком. Вместо этого мы разбиваем его на две части по 16 бит. Нижние биты сохраняются в первых 16 битах записи в IDT, а старшие 16 бит - в последних 16 битах записи. Все это сделано для совместимости с 286-ми процессорами. Как видишь, Intel выделывает такие номера на регулярной основе и во многих-многих местах!
В записи IDT нам осталось прописать тип, обозначив таким образом, что все это делается, чтобы отловить прерывание. Еще нам нужно задать офсет сегмента кода ядра. GRUB задает GDT за нас. Каждая запись GDT имеет длину 8 байт, где дескриптор кода ядра - это второй сегмент, так что его офсет составит 0x08 (подробности не влезут в эту статью). Гейт прерывания представлен как 0x8e. Оставшиеся в середине 8 бит заполняем нулями. Таким образом, мы заполним запись IDT, которая соответствует клавиатурному прерыванию.
Когда с маппингом IDT будет покончено, нам надо будет сообщить процессору, где находится IDT. Для этого существует ассемблерная инструкция lidt, она принимает один операнд. Им служит указатель на дескриптор структуры, которая описывает IDT.
С дескриптором никаких сложностей. Он содержит размер IDT в байтах и его адрес. Я использовал массив, чтобы вышло компактнее. Точно так же можно заполнить дескриптор при помощи структуры.
В переменной idr_ptr у нас есть указатель, который мы передаем инструкции lidt в функции load_idt() .
Load_idt: mov edx, lidt sti ret
Дополнительно функция load_idt() возвращает прерывание при использовании инструкции sti .
Заполнив и загрузив IDT, мы можем обратиться к IRQ клавиатуры, используя маску прерывания, о которой мы говорили ранее.
Void kb_init(void) { write_port(0x21 , 0xFD); }
0xFD - это 11111101 - включаем только IRQ1 (клавиатуру).
Функция - обработчик прерывания клавиатуры
Итак, мы успешно привязали прерывания клавиатуры к функции keyboard_handler , создав запись IDT для прерывания 0x21. Эта функция будет вызываться каждый раз, когда ты нажимаешь на какую-нибудь кнопку.
Keyboard_handler: call keyboard_handler_main iretd
Эта функция вызывает другую функцию, написанную на C, и возвращает управление при помощи инструкций класса iret. Мы могли бы тут написать весь наш обработчик, но на C кодить значительно легче, так что перекатываемся туда. Инструкции iret/iretd нужно использовать вместо ret , когда управление возвращается из функции, обрабатывающей прерывание, в программу, выполнение которой было им прервано. Этот класс инструкций поднимает флаговый регистр, который попадает в стек при вызове прерывания.
Void keyboard_handler_main(void) { unsigned char status; char keycode; /* Пишем EOI */ write_port(0x20, 0x20); status = read_port(KEYBOARD_STATUS_PORT); /* Нижний бит статуса будет выставлен, если буфер не пуст */ if (status & 0x01) { keycode = read_port(KEYBOARD_DATA_PORT); if(keycode < 0) return; vidptr = keyboard_map; vidptr = 0x07; } }
Здесь мы сначала даем сигнал EOI (End Of Interrupt, окончание обработки прерывания), записав его в командный порт PIC. Только после этого PIC разрешит дальнейшие запросы на прерывание. Нам нужно читать два порта: порт данных 0x60 и порт команд (он же status port) 0x64.
Первым делом читаем порт 0x64, чтобы получить статус. Если нижний бит статуса - это ноль, значит, буфер пуст и данных для чтения нет. В других случаях мы можем читать порт данных 0x60. Он будет выдавать нам код нажатой клавиши. Каждый код соответствует одной кнопке. Мы используем простой массив символов, заданный в файле keyboard_map.h , чтобы привязать коды к соответствующим символам. Затем символ выводится на экран при помощи той же техники, что мы применяли в первой версии ядра.
Чтобы не усложнять код, я здесь обрабатываю только строчные буквы от a до z и цифры от 0 до 9. Ты с легкостью можешь добавить спецсимволы, Alt, Shift и Caps Lock. Узнать, что клавиша была нажата или отпущена, можно из вывода командного порта и выполнять соответствующее действие. Точно так же можешь привязать любые сочетания клавиш к специальным функциям вроде выключения.
Теперь ты можешь собрать ядро, запустить его на реальной машине или на эмуляторе (QEMU) так же, как и в первой части.
Помимо того, сайта, важно знать, как правильно его применить с максимальной пользой для внутренней и внешней оптимизации сайта.
Уже очень много статей написано на тему того как сделать семантическое ядро, поэтому, в рамках данной статьи, я хочу обратить Ваше внимание на некоторые особенности и детали, которые помогут Вам правильно использовать семантическое ядро, и тем самым, помочь раскрутить интернет-магазин или сайт. Но сперва, вкратце дам свое определение семантическому ядру сайта.
Что такое семантическое ядро сайта?
Семантическое ядро сайта - это список, набор, массив, совокупность ключевых слов и фраз, которые запрашиваются пользователями (Вашими потенциальными посетителями) в браузерах поисковых систем, чтобы найти интересующую информацию.
Зачем нужно веб-мастеру составлять семантическое ядро?
Исходя из определения семантического ядра, возникает масса очевидных ответов на этот вопрос.
Владельцам интернет-магазинов важно знать, каким образом потенциальные покупатели пытаются найти тот товар или услугу, которую владелец интернет-магазина желает продать или предоставить. От этого понимания напрямую зависит положение интернет-магазина в поисковой выдаче. Чем более соответствует наполнение интернет-магазина покупательским поисковым запросам - тем ближе интернет-магазин к ТОПу поисковой выдачи. А значит, конверсия посетителей в покупатели будет выше и качественнее.
Для блоггеров, которые активно занимаются монетизацией своих блогов (манимейкингом), также важно быть в ТОПе поисковой выдачи по тематике релевантной содержанию блога. Увеличение поискового трафика несет больше прибыли от показов и кликов из контекстной рекламы на сайте, показов и кликов по рекламным блокам партнёрских программ и рост прибыли по другим видам заработка.
Чем больше на сайте оригинального и полезного контента - тем ближе сайт к ТОПу. Жизнь существует преимущественно на первой странице выдачи поисковых систем. Поэтому, знание того как сделать семантическое ядро является необходимым для SEO любого сайта, интернет-магазина.
Иногда веб-мастера и владельцы интернет-магазинов задаются вопросом - где брать качественный и релевантный контент? Ответ исходит из вопроса - нужно создавать контент в соответствии с ключевыми запросами пользователей. Чем больше поисковые системы будут считать контент Вашего сайта релевантным (подходящим) ключевым словам пользователей - тем лучше для Вас. Кстати, отсюда возникает ответ на вопрос - где брать разнообразие тематики контента? Всё просто - анализируя поисковые запросы пользователей, можно узнать чем они интересуются и в какой форме. Таким образом, сделав семантическое ядро сайта, можно написать ряд статей и/или описаний для товаров интернет-магазина, оптимизируя каждую страницу для определенного ключевого слова (поискового запроса).
К примеру, данную статью я решил оптимизировать по ключевому запросу "как сделать семантическое ядро", потому что конкуренция по данному запросу ниже, чем по запросу "как создать семантическое ядро" или "как составить семантическое ядро". Таким образом, мне гораздо легче пробиться к ТОПу выдачи поисковых систем по этому запросу абсолютно бесплатными методами раскрутки.
Как сделать семантическое ядро, с чего начать?
Для составления семантического ядра существует ряд популярных он-лайн сервисов.
Самым популярным сервисом, на мой взгляд, является статистика ключевых слов Яндекса - http://wordstat.yandex.ru/
При помощи данного сервиса можно собрать подавляющее большинство поисковых запросов в различных словоформах и комбинациях для любой тематики. Например, в левой колонке мы видим статистику количества запросов не только по ключевой фразе "семантическое ядро", но и статистику по различным комбинациям данной ключевой фразы в разных спряжениях и с разбавочными и дополнительными словами. В левой колонке мы видим статистику поисковых фраз, которые искали вместе с ключевой фразой "семантическое ядро". Эта информация может быть ценной, хотя бы в качестве источника тем для создания нового, релевантного Вашему сайту, контента. Ещё хочу упомянуть одну особенность этого сервиса - Вы можете уточнить регион. Благодаря этой опции Вы можете более точно узнать количество и характер нужных Вам поисковых запросов по нужному региону.

Ещё одним сервисом для составления семантического ядра является статистика поисковых запросов рамблера - http://adstat.rambler.ru/

На мой субъективный взгляд, данным сервисом можно пользоваться в том случае, когда идёт битва за привлечение на свой сайт каждого единичного пользователя. Здесь можно уточнить некоторые низкочастотные и long tail запросы, обращение пользователей по ним составляет приблизительно от 1 до 5-10 в месяц, т.е. очень мало. Сразу же оговорюсь, что в дальнейшем мы рассмотрим тему классификации ключевых слов и особенности каждой группы с точки зрения их применения. Поэтому, лично я крайне редко пользуюсь данной статистикой, как правило в тех случаях, если я занимаюсь или узкоспециализированного сайта.
Для формирования семантического ядра сайта также можно пользоваться подсказками, которые выпадают при вводе поискового запроса в браузере поисковика.


И ещё один вариант для жителей Украины пополнить список ключевых слов для семантического ядра сайта - просмотреть статистику сайтов на - http://top.bigmir.net/

Выбрав нужную тематику раздела, ищем открытую статистику наиболее посещаемого и подходящего по тематике сайта

Как видите, интересующая статистика не всегда может быть открытой, как правило, веб-мастера скрывают её. Тем не менее, в качестве дополнительного источника ключевых слов тоже может сгодиться.
Кстати, о том как оформить красиво в табличном виде в Excel весь список ключевых слов Вас научит замечательная статья Глобатора (Михаила Шакина) - http://shakin.ru/seo/keyword-suggestion.html Там же можно прочесть о том как сделать семантическое ядро для англоязычных проектов.
Что делать дальше со списком ключевых слов?
В первую очередь чтобы сделать семантическое ядро, я рекомендую структурировать список ключевых слов - разбить его на условные группы: на высокочастотные (ВЧ), среднечастотные (СЧ) и назкочастотные (НЧ) ключевые слова. Важно, чтобы в данные группы попадали ключевые слова очень близкие по морфологии и тематике. Сделать это удобнее всего в виде таблицы. Я это делаю приблизительно так:

Верхняя строка таблицы - это высокочастотные (ВЧ) поисковые запросы (написаны красным). Их я поставил во главе тематических колонок, в каждую ячейку которых я отсортировал среднечастотные (СЧ) и низкочастотные (НЧ) поисковые запросы максимально однородно по тематике. Т.е. к каждому ВЧ запросу я привязал наиболее подходящие группы СЧ и НЧ запросов. Каждая ячейка СЧ и НЧ запросов - это будущая статья, которую я пишу и оптимизирую строго под набор ключевых слов в ячейке. В идеале, одна статья должна соответствовать одному ключевому слову (поисковому запросу), но это очень рутинная и затратная по времени работа, ведь таких ключевых слов могут быть тысячи! Поэтому, если их очень много, нужно выделить для себя самые значимые, а остальные отсеять. Также, можно оптимизировать будущую статью под 2 - 4 СЧ и НЧ ключевых слова.
Для интернет-магазинов, СЧ и НЧ поисковые запросы как правило, являются названиями товаров. Поэтому, здесь не возникает особых трудностей внутренняя оптимизация каждой страницы интернет-магазина, просто это длительный процесс. Он тем дольше, чем больше товаров в интернет-магазине.
Зеленым цветом я выделил те ячейки, на которые у меня уже готовы статьи, т.о. я в дальнейшем не запутаюсь со списком готовых статей.
О том как нужно оптимизировать и писать статьи для сайта я расскажу в одной из будущих статей.
Итак, сделав такую таблицу, Вы можете иметь весьма четкое представление о том, как можно сделать семантическое ядро сайта.
В итоге данной статьи, хочу сказать, что здесь мы в какой-то степени коснулись детализации вопроса о раскрутке интернет-магазина . Наверняка, прочитав некоторые мои статьи о раскрутке интернет-магазина Вам пришла мысль о том, что составление семантического ядра сайта и внутренняя оптимизация являются взаимосвязанными и взаимозависящими мероприятиями. Я надеюсь, что смог аргументировать важность и первоочередность вопроса - как сделать семантическое ядро сайта.