Что дает кеш 3 уровня. На что влияет кэш процессора L1 L2 L3
При выполнении различных задач в процессор вашего компьютера поступают необходимые блоки информации из оперативной памяти. Обработав их ЦП записывает полученные результаты вычислений в память и получает на обработку последующие блоки данных. Так продолжается до тех пор, пока поставленная задача не будет выполнена.
Вышеупомянутые процессы производятся на очень большой скорости. Однако скорость даже самой быстрой оперативной памяти значительно меньше скорости любого слабого процессора. Каждое действие, будь то запись на неё информации или считывание с неё занимают много времени. Скорость работы оперативной памяти в десятки раз ниже скорости процессора.
Не смотря на такую разницу в скорости обработки информации, процессор ПК не простаивает без дела и не ожидает, когда ОЗУ выдаст и примет данные. Процессор всегда работает и всё благодаря присутствию в нем кэш памяти.
Кэш — особый вид оперативной памяти. Процессор использует память кэша для хранения тех копий информации из основной оперативной памяти компьютера, вероятность обращения к которым в ближайшее время очень велика.
По сути кэш-память выполняет роль быстродействующего буфера памяти хранящего информацию, которая может потребоваться процессору. Таким образом процессор получает необходимые данные в десятки раз быстрее, чем при считывании их из оперативной памяти.
Основным отличием кэш памяти от обычного буфера являются встроенные логические функции. В буфере хранятся случайные данные, которые как правило обрабатываются по схеме » получен первым, выдан первым» либо » получен первым, выдан последним». В кэш памяти содержатся данные, вероятность обращения к которым в ближайшее время очень велика. Поэтому благодаря «умному кэшу» процессор может работать с полной скоростью и не ожидать данные, извлекаемые из более медленной оперативной памяти.
Основные типы и уровни кэш-памяти L1 L2 L3
Кэш память выполнена в виде микросхем статической оперативной памяти (SRAM), которые устанавливаются на системной плате либо встроены в процессор. В сравнении с другими видами памяти, статическая память способна работать на очень больших скоростях.
Скорость кэша зависит от объема конкретной микросхемы, Чем больше объем микросхемы, тем труднее добиться высокой скорости для её работы. Учитывая данную особенность, при изготовлении кэш память процессора выполняют в виде нескольких небольших блоков, именуемых уровнями. Самой распространенной на сегодняшний день считается трехуровневая система кеша L1,L2, L3:
Кэш память первого уровня L1 — самая маленькая по объему (всего несколько десятков килобайт), но самая быстрая по скорости и наиболее важная. Она содержит данные наиболее часто используемые процессором и работает без задержек. Обычно количество микросхем памяти уровня L1 равно количеству ядер процессора, при этом каждое ядро получает доступ только к своей микросхеме L1.
Кэш память уровня L2 по скорости уступает памяти L1, но выигрывает в объеме, который измеряется уже в нескольких сотнях килобайт. Она предназначена для временного хранения важной информации, вероятность обращения к которой ниже, чем у информации хранящейся в кэше L1.
Третий уровень кэш памяти L3 — имеет самый большой объем из трех уровней (может достигать десятков мегабайт), но и обладает самой медленной скоростью, которая всё же значительно выше скорости оперативной памяти. Кэш память L3 служит общей для всех ядер процессора. Уровень памяти L3 предназначен для временного хранения тех важных данных, вероятность обращения к которым чуть ниже, чем у информации которая хранится в первых двух уровнях L1, L2. Она также обеспечивает взаимодействие ядер процессора между собой.
Некоторые модели процессоров выполнены с двумя уровнями кэш памяти, в которых L2 совмещает все функции L2 и L3.
Когда полезен большой объем кэша.
Значительный эффект от большого объема кэша вы ощутите при использовании программ архиваторов, в 3D играх, во время обработки и кодирования видео. В относительно «легких» программах и приложениях разница практически не заметна (офисные программы, плееры и т.п).
Насколько важен кэш L3 для процессоров AMD?
Действительно, имеет смысл оснащать многоядерные процессоры выделенной памятью, которая будет использоваться совместно всеми доступными ядрами. В данной роли быстрый кэш третьего уровня (L3) может существенно ускорить доступ к данным, которые запрашиваются чаще всего. Тогда ядрам, если существует такая возможность, не придётся обращаться к медленной основной памяти (ОЗУ, RAM).
По крайней мере, в теории. Недавно AMD анонсировала процессор Athlon II X4, представляющий собой модель Phenom II X4 без кэша L3, намекая на то, что он не такой и необходимый. Мы решили напрямую сравнить два процессора (с кэшем L3 и без), чтобы проверить, как кэш влияет на производительность.
Как работает кэш?
Перед тем, как мы углубимся в тесты, важно понять некоторые основы. Принцип работы кэша довольно прост. Кэш буферизует данные как можно ближе к вычислительным ядрам процессора, чтобы снизить запросы CPU в более отдалённую и медленную память. У современных настольных платформ иерархия кэша включает целых три уровня, которые предваряют доступ к оперативной памяти. Причём кэши второго и, в частности, третьего уровней служат не только для буферизации данных. Их цель заключается в предотвращении перегрузки шины процессора, когда ядрам необходимо обменяться информацией.
Попадания и промахи
Эффективность архитектуры кэшей измеряется процентом попаданий. Запросы данных, которые могут быть удовлетворены кэшем, считаются попаданиями. Если данный кэш не содержит нужные данные, то запрос передаётся дальше по конвейеру памяти, и засчитывается промах. Конечно, промахи приводят к большему времени, которое требуется для получения информации. В результате в вычислительном конвейере появляются "пузырьки" (простои) и задержки. Попадания, напротив, позволяют поддержать максимальную производительность.
Запись в кэш, эксклюзивность, когерентность
Политики замещения диктуют, как в кэше освобождается место под новые записи. Поскольку данные, записываемые в кэш, рано или поздно должны появиться в основной памяти, системы могут делать это одновременно с записью в кэш (write-through) или могут маркировать данные области как "грязные" (write-back), а выполнять запись в память тогда, когда она будет вытесняться из кэша.
Данные в нескольких уровнях кэша могут храниться эксклюзивно, то есть без избыточности. Тогда вы не найдёте одинаковых строчек данных в двух разных иерархиях кэша. Либо кэши могут работать инклюзивно, то есть нижние уровни кэша гарантированно содержат данные, присутствующие в верхних уровнях кэша (ближе к процессорному ядру). У AMD Phenom используются эксклюзивный кэш L3, а Intel следует стратегии инклюзивного кэша. Протоколы когерентности следят за целостностью и актуальностью данных между разными ядрами, уровнями кэшей и даже процессорами.
Объём кэша
Больший по объёму кэш может содержать больше данных, но при этом наблюдается тенденция увеличения задержек. Кроме того, большой по объёму кэш потребляет немалое количество транзисторов процессора, поэтому важно находить баланс между "бюджетом" транзисторов, размером кристалла, энергопотреблением и производительностью/задержками.
Ассоциативность
Записи в оперативной памяти могут привязываться к кэшу напрямую (direct-mapped), то есть для копии данных из оперативной памяти существует только одна позиция в кэше, либо они могут быть ассоциативны в n-степени (n-way associative), то есть существует n возможных расположений в кэше, где могут храниться эти данные. Более высокая степень ассоциативности (вплоть до полностью ассоциативных кэшей) обеспечивает наилучшую гибкость кэширования, поскольку существующие данные в кэше не нужно переписывать. Другими словами, высокая n-степень ассоциативности гарантирует более высокий процент попаданий, но при этом увеличивается задержка, поскольку требуется больше времени на проверку всех этих ассоциаций для попадания. Как правило, наибольшая степень ассоциации разумна для последнего уровня кэширования, поскольку там доступна максимальная ёмкость, а поиск данных за пределами этого кэша приведёт к обращению процессора к медленной оперативной памяти.
Приведём несколько примеров: у Core i5 и i7 используется 32 кбайт кэша L1 с 8-way ассоциативностью для данных и 32 кбайт кэша L1 с 4-way для инструкций. Понятно желание Intel, чтобы инструкции были доступны быстрее, а у кэша L1 для данных был максимальный процент попаданий. Кэш L2 у процессоров Intel обладает 8-way ассоциативностью, а кэш L3 у Intel ещё "умнее", поскольку в нём реализована 16-way ассоциативность для максимизации попаданий.
Однако AMD следует другой стратегии с процессорами Phenom II X4, где используется кэш L1 с 2-way ассоциативностью для снижения задержек. Чтобы компенсировать возможные промахи ёмкость кэша была увеличена в два раза: 64 кбайт для данных и 64 кбайт для инструкций. Кэш L2 имеет 8-way ассоциативность, как и у дизайна Intel, но кэш L3 у AMD работает с 48-way ассоциативностью. Но решение выбора той или иной архитектуры кэша нельзя оценивать без рассмотрения всей архитектуры CPU. Вполне естественно, что практическое значение имеют результаты тестов, и нашей целью как раз была практическая проверка всей этой сложной многоуровневой структуры кэширования.
Сегодняшняя статья не является самостоятельным материалом - она просто продолжает исследование производительности трех поколений архитектуры Core в равных условиях (начатое в конце прошлого года и продолженное недавно). Правда, сегодня мы сделаем небольшой шаг в сторону - часто́ты ядер и кэш-памяти останутся теми же, что и ранее, а вот емкость последней уменьшится. Зачем это нужно? Мы использовали «полный» Core i7 двух последних поколений для чистоты эксперимента, тестируя его с включенной и отключенной поддержкой технологии Hyper-Threading, поскольку вот уже полтора года как Core i5 снабжаются не 8, а 6 МиБ L3. Понятно, что влияние емкости кэш-памяти на производительность не так уж велико, как иногда принято считать, но оно есть, и никуда от него не деться. К тому же, Core i5 являются более массовыми продуктами, чем Core i7, а в первом поколении по этому параметру их никто «не обижал». Зато раньше их чуть ограничивали по-другому: тактовая частота UnCore в i5 первого поколения составляла всего 2,13 ГГц, так что наш «Nehalem» - это не совсем представитель 700-й линейки на частоте 2,4 ГГц, а немного более быстрый процессор. Однако сильно расширять список участников и переделывать условия тестирования мы сочли излишним - все равно, как мы уже не раз предупреждали, тестирования этой линейки никакой новой практической информации не несут: реальные процессоры работают совсем в других режимах. А вот желающим досконально разобраться во всех тонких моментах, как нам кажется, такое тестирование будет интересно.
Конфигурация тестовых стендов
Мы решили ограничиться всего четырьмя процессорами, причем главных участников будет два: оба четырехъядерных Ivy Bridge, но с разной емкостью кэш-памяти третьего уровня. Третий - «Nehalem HT»: в прошлый раз по итоговому баллу он оказался почти идентичен «Ivy Bridge просто». И «просто Nehalem» который, как мы уже сказали, чуть-чуть быстрее настоящего Core i5 первого поколения, работающего на частоте 2,4 ГГц (из-за того, напомним, что в 700-й линейке частота UnCore была немного ниже), но не слишком радикально. Зато и сравнение интересно: с одной стороны - два шага улучшения микроархитекутры, с другой - кэш-память ограничили. Априори можно предположить, что первое в большинстве случаев перевесит, но вот насколько и вообще - как сопоставимы «первые» и «третьи» i5 (с поправкой на частоту UnCore, конечно, хотя если будет много желающих увидеть абсолютно точное сравнение, мы и его потом сделаем) - уже хорошая тема для исследования.
Тестирование
Традиционно, мы разбиваем все тесты на некоторое количество групп и приводим на диаграммах средний результат по группе тестов/приложений (детально с методикой тестирования вы можете ознакомиться в отдельной статье). Результаты на диаграммах приведены в баллах, за 100 баллов принята производительность референсной тестовой системы сайт образца 2011 года. Основывается она на процессоре AMD Athlon II X4 620, ну а объем памяти (8 ГБ) и видеокарта () являются стандартными для всех тестирований «основной линейки» и могут меняться только в рамках специальных исследований. Тем, кто интересуется более подробной информацией, опять-таки традиционно предлагается скачать таблицу в формате Microsoft Excel , в которой все результаты приведены как в преобразованном в баллы, так и в «натуральном» виде.
Интерактивная работа в трёхмерных пакетах
Некоторое влияние емкости кэш-памяти есть, однако оно менее 1%. Соответственно, оба Ivy Bridge можно считать идентичными друг другу, ну а улучшения архитектуры позволяют новым Core i5 спокойно обгонять старые Core i7 точно также, как это делают новые Core i7.
Финальный рендеринг трёхмерных сцен
В данном случае, естественно, никакие усовершенствования не могут скомпенсировать увеличение количества обрабатываемых потоков, но сегодня для нас самым важным является не это, а полное отсутствие влияния емкости кэш-памяти на производительность. Вот Celeron и Pentium, как мы уже установили , разные процессоры, так что программы рендеринга чувствительны к емкости L3, однако лишь тогда, когда последнего мало. А 6 МиБ на четыре ядра, как видим, вполне достаточно.
Упаковка и распаковка
Естественно, эти задачи восприимчивы к емкости кэш-памяти, однако и здесь эффект от ее увеличения с 6 до 8 МиБ достаточно скромный: примерно 3,6%. Более интересно, на самом деле, сравнение с первым поколением - архитектурные улучшения позволяют новым i5 на равных частотах «громить» даже старые i7, но это в общем зачете: благодаря тому, что два теста из четырех однопоточные, а еще один двухпоточный. Сжатие данных силами 7-Zip, естественно, быстрее всего на «Nehalem HT»: восемь потоков всегда быстрее четырех сравнимой производительности. А вот если ограничиться всего четырьмя, то наш «Ivy Bridge 6М» проигрывает не только своему прародителю, но и старичку Nehalem: улучшения микроархитектуры полностью пасуют перед уменьшением емкости кэш-памяти.
Кодирование аудио
Несколько неожиданным оказался не размер разницы между двумя Ivy Bridge, а то, что она вообще есть. Правда настолько копеечная, что ее можно и на особенности округления или погрешности измерения списать.
Компиляция
Важны потоки, но важна и емкость кэш-памяти. Однако, как обычно, не слишком - порядка 1,5%. Более любопытно сравнение с первым поколением Core при отключенном Hyper-Threading: «по очкам» новенький Core i5 даже на равной частоте побеждает, но один из трех компиляторов (производства Microsoft, если быть точным) отработал на обоих процессорах за одинаковое время. Даже с преимуществом в 5 секунд у более старого - притом, что в этой программе у «полнокэшевого» Ivy Bridge результаты на 4 секунды лучше, чем у Nehalem. В общем, и здесь нельзя считать, что уменьшение емкости L3 как-то сильно повлияло на Core i5 второго и третьего поколения, но есть и нюансы.
Математические и инженерные расчёты
Опять менее 1% разницы со «старшим» кристаллом и опять убедительная победа над первым поколением во всех его видах. Что скорее правило, чем исключение для подобных малопоточных тестов, но почему бы в нем в очередной раз не убедиться? Особенно в таком вот рафинированном виде, когда (в отличие от тестов в штатном режиме) не мешает разница в частотах («стандартных» или появляющаяся из-за работы Turbo Boost).
Растровая графика
Но и при более полной утилизации многопоточности картина не всегда меняется. А емкость кэш-памяти не дает вовсе ничего.
Векторная графика
И здесь аналогично. Правда и потоков вычисления нужна всего парочка.
Кодирование видео
В отличие от этой группы, где, тем не менее, даже Hyper-Threading не позволяет Nehalem бороться на равных с последователями более новых поколений. А вот им не слишком мешает уменьшение емкости кэш-памяти. Точнее, практически вообще не мешает, поскольку разница опять менее 1%.
Офисное ПО
Как и следовало ожидать, никакого прироста производительности от увеличения емкости кэш-памяти (точнее, ее падения от уменьшения) нет. Хотя если посмотреть на подробные результаты, то видно, что единственный многопоточный тест этой группы (а именно распознавание текста в FineReader) выполняется примерно на 1,5% быстрее при 8 МиБ L3, нежели на 6 МиБ. Казалось бы - что такое 1,5%? С точки зрения практики - ничто. А вот с исследовательской точки зрения уже интересно: как видим, именно многопоточным тестам чаще всего не хватает кэш-памяти. В результате разница (пусть и небольшая) иногда находится даже там, где ее быть, вроде бы, не должно. Хотя ничего такого уж необъяснимого в этом нет - грубо говоря, в малопоточных тестах мы имеем 3-6 МиБ на поток, а вот в многопоточных там же получается 1,5 МиБ. Первого - много, а вот второго может оказаться и не совсем достаточно.
Java
Впрочем, Java-машина с такой оценкой не согласна, но и это объяснимо: как мы уже не раз писали, она очень хорошо оптимизирована вовсе не под х86-процессоры, а под телефоны и кофеварки, где ядер может быть много, но вот кэш-памяти очень мало. А иногда и ядер, и кэш-памяти мало - дорогие ресурсы как по площади кристалла, так и по энергопотреблению. И, если с ядрами и мегагерцами что-то сделать получается, то вот с кэшом все сложнее: в четырехъядерной Tegra 3 его, к примеру, всего 1 МиБ. Понятно, что JVM может «схрюпать» и больше (как и все системы с байт-кодом), что мы уже видели сравнивая Celeron и Pentium, но более 1,5 МиБ на поток ей если и может пригодиться, то не в тех задачах, которые вошли в SPECjvm 2008.
Игры
На игры у нас были большие надежды, поскольку к емкости кэш-памяти они нередко оказываются более требовательными чем даже архиваторы. Но бывает такое тогда, когда ее совсем мало, а 6 МиБ - как видим, достаточно. Да и, опять же, процессоры уровня четырехъядерных Core любых поколений даже на частоте 2,4 ГГц слишком мощное решение для используемых игровых приложений, так что узким местом явно будут не они, а прочие компоненты системы. Поэтому мы решили стряхнуть пыль с режимов с низким качеством графики - понятно, что для таких систем он слишком уж синтетичен, но у нас и все тестирование синтетическое:)
Когда не мешают всякие там видеокарты и прочее, разница между двумя Ivy Bridge достигает уже «безумных» 3%: и в этом случае можно не обращать внимания на практике, но для теории - немало. Больше вышло как раз только в архиваторах.
Многозадачное окружение
Где-то мы уже такое видели. Ну да - когда тестировали шестиядерные процессоры под LGA2011. И вот ситуация повторяется: нагрузка что ни на есть многопоточная, часть используемых программ до кэш-памяти «жадная», а вот ее увеличение только снижает среднюю производительность. Чем это можно объяснить? Разве что тем, что усложняется арбитраж и увеличивается количество промахов. Причем, заметим, происходит такое только тогда, когда емкость L3 относительно велика и одновременно работающих потоков вычисления не менее четырех - в бюджетном сегменте совсем другая картина. Во всяком случае, как показало наше недавнее тестирование Pentium и Celeron, для двухъядерных процессоров увеличение L3 с 2 до 3 МиБ добавляет 6% производительности. А вот четырех- и шестиядерным не дает, мягко говоря ничего. Даже менее, чем ничего.
Итого
Закономерный общий итог: поскольку нигде существенной разницы между процессорами с разным объемом L3 не обнаружилось, нет ее и в «общем и целом». Таким образом, расстраиваться по поводу уменьшения емкости кэш-памяти во втором и третьем поколении Core i5 поводов нет - предшественники первого поколения им все равно не конкуренты. Да и старые Core i7 в среднем тоже демонстрируют лишь аналогичный уровень производительности (разумеется, в основном за счет отставания в малопоточных приложениях - а так есть сценарии, с которыми в равных условиях они справляются быстрее). Но, как мы уже говорили, на практике реальные процессоры находятся далеко не в равных условиях по частотам, так что практическая разница между поколениями больше, чем можно получить в таких вот исследованиях.
Открытым остается лишь один вопрос: нам пришлось сильно снизить тактовую частоту для обеспечения равенства условий с первым поколением Core, но сохранятся ли замеченные закономерности в более близких к реальности условиям? Ведь из того, что четыре низкоскоростных потока вычислений не видят разницы между 6 и 8 МиБ кэш-памяти, не следует, что она не обнаружится в случае четырех высокоскоростных. Правда, не следует и обратного, так что для того, чтобы окончательно закрыть тему теоретических исследований, нам понадобится еще одна лабораторная работа, которой мы и займемся в следующий раз.
Компьютерные процессоры сделали значительный рывок в развитии за последние несколько лет. Размер транзисторов с каждым годом уменьшается, а производительность растет. При этом закон Мура уже становится неактуальным. Что касается производительности процессоров, то следует учитывать, не только количество транзисторов и частоту, но и объем кэша.
Возможно, вы уже слышали о кэш памяти когда искали информацию о процессорах. Но, обычно, мы не обращаем много внимания на эти цифры, они даже не сильно выделяются в рекламе процессоров. Давайте разберемся на что влияет кэш процессора, какие виды кэша бывают и как все это работает.
Если говорить простыми словами, то кэш процессора это просто очень быстрая память. Как вы уже знаете, у компьютера есть несколько видов памяти. Это постоянная память, которая используется для хранения данных, операционной системы и программ, например, SSD или жесткий диск. Также в компьютере используется оперативная память. Это память со случайным доступом, которая работает намного быстрее, по сравнению с постоянной. И наконец у процессора есть ещё более быстрые блоки памяти, которые вместе называются кэшем.
Если представить память компьютера в виде иерархии по её скорости, кэш будет на вершине этой иерархии. К тому же он ближе всего к вычислительным ядрам, так как является частью процессора.
Кэш память процессора представляет из себя статическую память (SRAM) и предназначен для ускорения работы с ОЗУ. В отличие от динамической оперативной памяти (DRAM), здесь можно хранить данные без постоянного обновления.
Как работает кэш процессора?
Как вы, возможно, уже знаете, программа — это набор инструкций, которые выполняет процессор. Когда вы запускаете программу, компьютеру надо перенести эти инструкции из постоянной памяти в процессору. И здесь вступает в силу иерархия памяти. Сначала данные загружаются в оперативную память, а потом передаются в процессор.
В наши дни процессор может обрабатывать огромное количество инструкций в секунду. Чтобы по максимуму использовать свои возможности, процессору необходима супер быстрая память. Поэтому был разработан кэш.
Контроллер памяти процессора выполняет работу по получению данных из ОЗУ и отправке их в кэш. В зависимости от процессора, используемого в вашей системе, этот контроллер может быть размещен в северном мосту материнской плате или в самом процессоре. Также кэш хранит результаты выполнения инструкций в процессоре. Кроме того, в самом кэше процессора тоже есть своя иерархия.
Уровни кэша процессора — L1, L2 и L3
Веся кэш память процессора разделена на три уровни: L1, L2 и L3. Эта иерархия тоже основана на скорости работы кэша, а также на его объеме.
- L1 Cache (кэш первого уровня) — это максимально быстрый тип кэша в процессоре. С точки зрения приоритета доступа, этот кэш содержит те данные, которые могут понадобиться программе для выполнения определенной инструкции;
- L2 Cache (кэш второго уровня процессора) — медленнее, по сравнению L1, но больше по размеру. Его объем может быть от 256 килобайт до восьми мегабайт. Кэш L2 содержит данные, которые, возможно, понадобятся процессору в будущем. В большинстве современных процессоров кэш L1 и L2 присутствуют на самих ядрах процессора, причём каждое ядро получает свой собственный кэш;
- L3 Cache (кэш третьего уровня) — это самый большой и самый медленный кэш. Его размер может быть в районе от 4 до 50 мегабайт. В современных CPU на кристалле выделяется отдельное место под кэш L3.

На данный момент это все уровни кэша процессора, компания Intel пыталась создать кэш уровня L4, однако, пока эта технология не прижилась.
Для чего нужен кэш в процессоре?
Пришло время ответить на главный вопрос этой статьи, на что влияет кэш процессора? Данные поступают из ОЗУ в кэш L3, затем в L2, а потом в L1. Когда процессору нужны данные для выполнения операции, он пытается их найти в кэше L1 и если находит, то такая ситуация называется попаданием в кэш. В противном случае поиск продолжается в кэше L2 и L3. Если и теперь данные найти не удалось, выполняется запрос к оперативной памяти.
Теперь мы знаем, что кэш разработан для ускорения передачи информации между оперативной памятью и процессором. Время, необходимое для того чтобы получить данные из памяти называется задержкой (Latency). Кэш L1 имеет самую низкую задержку, поэтому он самый быстрый, кэш L3 — самую высокую. Когда данных в кэше нет, мы сталкиваемся с еще более высокой задержкой, так как процессору надо обращаться к памяти.
Раньше, в конструкции процессоров кєши L2 и L3 были были вынесены за пределы процессора, что приводило к высоким задержкам. Однако уменьшение техпроцесса, по которому изготавливаются процессоры позволяет разместить миллиарды транизисторов в пространстве, намного меньшем, чем раньше. Как результат, освободилось место, чтобы разместить кэш как можно ближе к ядрам, что ещё больше уменьшает задержку.
Как кэш влияет на производительность?
Влияние кэша на произвоидтельность компьютера напрямую зависит от его эффективности и количества попаданий в кэш. Ситуации, когда данных в кэше не оказывается очень сильно снижают общую производительность.
Представьте, что процессор загружает данные из кэша L1 100 раз подряд. Если процент попаданий в кэш будет 100%, процессору понадобиться 100 наносекунд чтобы получить эти данные. Однако, как только процент попаданий уменьшится до 99%, процессору нужно будет извлечь данные из кэша L2, а там уже задержка 10 наносекунд. Получится 99 наносекунд на 99 запросов и 10 наносекунд на 1 запрос. Поэтому уменьшение процента попаданий в кэш на 1% снижает производительность процессора 10%.
В реальном времени процент попаданий в кэш находится между 95 и 97%. Но как вы понимаете, разница в производительности между этими показателями не в 2%, а в 14%. Имейте в виду, что в примере, мы предполагаем, что прощенные данные всегда есть в кэше уровня L2, в реальной жизни данные могут быть удалены из кэша, это означает, что их придется получать из оперативной памяти, у которой задержка 80-120 наносекунд. Здесь разница между 95 и 97 процентами ещё более значительная.
Низкая производительность кэша в процессорах AMD Bulldozer и Piledriver была одной из основных причин, почему они проигрывали процессорам Intel. В этих процессорах кэш L1 разделялся между несколькими ядрами, что делало его очень не эффективным. В современных процессорах Ryzen такой проблемы нет.
Можно сделать вывод, чем больше объем кэша, тем выше производительность, поскольку процессор сможет получить в большем количестве случаев нужные ему данные быстрее. Однако, стоит обращать внимание не только на объем кэша процессора, но и на его архитектуру.
Выводы
Теперь вы знаете за что отвечает кэш процессора и как он работает. Дизайн кэша постоянно развивается, а память становится быстрее и дешевле. Компании AMD и Intel уже провели множество экспериментов с кэшем, а в Intel даже пытались использовать кэш уровня L4. Рынок процессоров развивается куда быстрее, чем когда-либо. Архитектура кэша будет идти в ногу с постоянно растущей мощностью процессоров.
Кроме того, многое делается для устранения узких мест, которые есть у современных компьютеров. Уменьшение задержки работы с памятью одна из самых важных частей этой работы. Будущее выглядит очень многообещающе.
Похожие записи.
Приветствуем вас на сайте GECID.com! Хорошо известно, что тактовая частота и количество ядер процессора напрямую влияют на уровень производительности, особенно в оптимизированных под многопоточность проектах. Мы же решили проверить, какую роль в этом играет кэш-память уровня L3?
Для исследования этого вопроса нам был любезно предоставлен интернет-магазином pcshop.ua 2-ядерный процессор с номинальной рабочей частотой 3,7 ГГц и 3 МБ кэш-памяти L3 с 12-ю каналами ассоциативности. В роли оппонента выступил 4-ядерный , у которого были отключены два ядра и снижена тактовая частота до 3,7 ГГц. Объем же кэша L3 у него составляет 8 МБ, и он имеет 16 каналов ассоциативности. То есть ключевая разница между ними заключается именно в кэш-памяти последнего уровня: у Core i7 ее на 5 МБ больше.


Если это ощутимо повлияет на производительность, тогда можно будет провести еще один тест с представителем серии Core i5, у которых на борту 6 МБ кэша L3.

Но пока вернемся к текущему тесту. Помогать участникам будет видеокарта и 16 ГБ оперативной памяти DDR4-2400 МГц. Сравнивать эти системы будем в разрешении Full HD.

Для начала начнем с рассинхронизированных живых геймплев, в которых невозможно однозначно определить победителя. В Dying Light на максимальных настройках качества обе системы показывают комфортный уровень FPS, хотя загрузка процессора и видеокарты в среднем была выше именно в случае Intel Core i7.

Arma 3 имеет хорошо выраженную процессорозависимость, а значит больший объем кэш-памяти должен сыграть свою позитивную роль даже при ультравысоких настройках графики. Тем более что нагрузка на видеокарту в обоих случаях достигала максимум 60%.
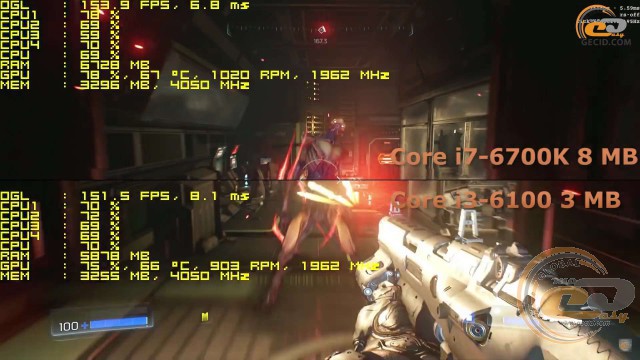
Игра DOOM на ультравысоких настройках графики позволила синхронизировать лишь первые несколько кадров, где перевес Core i7 составляет около 10 FPS. Рассинхронизация дельнейшего геймплея не позволяет определить степень влияния кэша на скорость видеоряда. В любом случае частота держалась выше 120 кадров/с, поэтому особого влияния даже 10 FPS на комфортность прохождения не оказывают.

Завершает мини-серию живых геймплеев Evolve Stage 2 . Здесь мы наверняка увидели бы разницу между системами, поскольку в обоих случаях видеокарта загружена ориентировочно на половину. Поэтому субъективно кажется, что уровень FPS в случае Core i7 выше, но однозначно сказать нельзя, поскольку сцены не идентичные.

Более информативную картину дают бенчмарки. Например, в GTA V можно увидеть, что за городом преимущество 8 МБ кэша достигает 5-6 кадров/с, а в городе - до 10 FPS благодаря более высокой загрузке видеокарты. При этом сам видеоускоритель в обоих случаях загружен далеко не на максимум, и все зависит именно от CPU.

Третий ведьмак мы запустили с запредельными настройками графики и высоким профилем постобработки. В одной из заскриптованных сцен преимущество Core i7 местами достигает 6-8 FPS при резкой смене ракурса и необходимости подгрузки новых данных. Когда же нагрузка на процессор и видеокарту опять достигают 100%, то разница уменьшается до 2-3 кадров.

Максимальный пресет графических настроек в XCOM 2 не стал серьезным испытанием для обеих систем, и частота кадров находилась в районе 100 FPS. Но и здесь больший объем кэш-памяти трансформировался в прибавку к скорости от 2 до 12 кадров/с. И хотя обоим процессорам не удалось по максимум загрузить видеокарту, вариант на 8 МБ и в этом вопросе местами преуспевал лучше.


Больше всего удивила игра Dirt Rally , которую мы запустили с пресетом очень высоко. В определенные моменты разница доходила до 25 кадров/с исключительно из-за большего объема кэш-памяти L3. Это позволяло на 10-15% лучше загружать видеокарту. Однако средние показатели бенчмарка показали более скромную победу Core i7 - всего 11 FPS.


Интересная ситуация получилась и с Rainbow Six Siege : на улице, в первых кадрах бенчмарка, преимущество Core i7 составляло 10-15 FPS. Внутри помещения загрузка процессоров и видеокарты в обоих случаях достигла 100%, поэтому разница уменьшилась до 3-6 FPS. Но в конце, когда камера вышла за пределы дома, отставание Core i3 опять местами превышало 10 кадров/с. Средний же показатель оказался на уровне 7 FPS в пользу 8 МБ кэша.


The Division при максимальном качестве графики также хорошо реагирует на увеличение объема кэш памяти. Уже первые кадры бенчмарка по полной загрузили все потоки Core i3, а вот общая нагрузка на Core i7 составляла 70-80%. Однако разница в скорости в эти моменты составляла всего 2-3 FPS. Чуть позже нагрузка на оба процессора достигла 100%, а разница в определенные моменты уже была за Core i3, но лишь на 1-2 кадра/с. В среднем же она составила около 1 FPS в пользу Core i7.

В свою очередь бенчмарк Rise of Tomb Rider при высоких настройках графики во всех трех тестовых сценах наглядно показал преимущество процессора с значительно большим объемом кэш памяти. Средние показатели у него на 5-6 FPS лучше, но если внимательно посмотреть каждую сцену, то местами отставание Core i3 превышает 10 кадров/с.


А вот при выборе пресета с очень высокими настройками возрастает нагрузка на видеокарту и процессоры, поэтому в большинстве своем разница между системами уменьшается до нескольких кадров. И лишь кратковременно Core i7 может показывать более значимые результаты. Средние показатели его преимущества по итогам бенчмарка снизились до 3-4 FPS.

Hitman также меньше подвержен влиянию кэш-памяти L3. Хотя и здесь при ультравысоком профиле детализации дополнительные 5 МБ обеспечили лучшую загрузку видеокарты, превратив это в дополнительные 3-4 кадра/с. Особо критичного влияния на производительность они не оказывают, но из чисто спортивного интереса приятно, что есть победитель.


Высокие настройки графики Deus ex: Mankind divided сразу же потребовали максимальной вычислительной мощности от обеих систем, поэтому разница в лучшем случае составляла 1-2 кадра в пользу Core i7, на что указывает и средний показатель.


Повторный запуск при ультравысоком пресете еще сильнее загрузил видеокарту, поэтому влияние процессора на общую скорость стало еще меньшим. Соответственно, разница в кэш-памяти L3 практически не влияла на ситуацию и средний FPS отличался менее чем на полкадра.

По итогам тестирования можно отметить, что влияние кэш-памяти L3 на производительность в играх действительно имеет место, но оно проявляется лишь тогда, когда видеокарта не загружена на полную мощность. В таких случаях можно было бы получить прирост в 5-10 FPS, если бы кэш увеличился в 2,5 раза. То есть ориентировочно получается, что при прочих равных каждый дополнительный МБ кэш-памяти L3 добавляет только 1-2 FPS к скорости отображения видеоряда.
Так что, если сравнивать соседние линейки, например, Celeron и Pentium, или модели с разным объем кэш-памяти L3 внутри серии Core i3, то основной прирост производительности достигается благодаря более высоким частотам, а потом и наличию дополнительных процессорных потоков и ядер. Поэтому, выбирая процессор, в первую очередь, все же, нужно ориентироваться на основные характеристики, а только потом обращать внимание на объем кэш-памяти.
На этом все. Спасибо за внимание. Надеемся, этот материал был полезным и интересным.
Статья прочитана 27046 раз(а)
| Подписаться на наши каналы | |||||